Benchmarking a Multimodal Agent
At Hedra, we recently launched a multimodal agent that can create images and video through conversation. What used to require manual work across multiple creative tools can now be done with natural language: describe what you want, refine it over multiple turns, reference earlier outputs, and keep going.
That product experience feels simple on the surface, but the system underneath is not. Agents are powerful, but they are also black boxes. Their behavior is nondeterministic, highly sensitive to prompts, and affected by changes to tools, orchestration, and model choice. If you want to improve an agent with confidence, a strong eval framework is not optional. It is the only way to know whether changes are actually making the product better.
That led us to build a benchmark around realistic conversations. Instead of testing the agent on isolated one-shot prompts, we record representative multi-turn scenarios and replay them later to see how the system behaves after changes to prompts, tools, orchestration, or models.
Why This Is Hard
Evaluating a multimodal agent is very different from evaluating a text-only system. In real use, a conversation might start with an image request, continue with a video based on that image, and then branch into edits or follow-up generations that depend on earlier outputs.
That means the benchmark has to capture more than just the final reply. It has to preserve the structure of the interaction itself: what the user asked for, what the agent did, and how assets created in one turn are referenced later in the conversation.
The biggest challenge is cost. Real image and video generation is expensive and slow, so running a large benchmark against live media providers is not practical. But simple mocks are not enough either. If an earlier turn creates an image and a later turn refers to that image, the agent still needs something that behaves like a real asset with a stable identity.
Our Approach
We solved this by creating benchmark scenarios from real agent interactions and then replaying those scenarios in a controlled environment.
When a scenario is authored, we capture the conversation turn by turn and keep the important structure intact. Later, when that scenario is replayed, the agent goes through the same overall workflow again, but media generation is simulated instead of sent to live providers. We still build each request as if it were going to a real provider, then assign a deterministic asset UUID based on the scenario and the asset's position in the sequence.
That deterministic UUID scheme is what makes the benchmark reliable. It lets us simulate multiple assets within a scenario and then verify that later tool calls reference the right ones at the right points in the trajectory. Because we compare both the overall path and the arguments passed to tools, those synthetic asset IDs need to stay stable across repeated runs of the same scenario. At the same time, each scenario uses its own salt, so different scenarios can run in parallel against the same local database without collisions.
.png&w=3840&q=75)
Another subtle challenge is that there is often more than one valid way for an agent to accomplish a goal. Two runs may take different tool paths, make slightly different intermediate decisions, and still produce an equally good outcome for the user. A useful eval framework has to account for that, rather than assuming there is only one exact sequence of actions that counts as correct.
.png&w=3840&q=75)
Note: analysing images helps the agent understand what was generated so we can craft better prompts.
Metric: Probability of accomplishing a set of scenarios
The final piece is scoring. For a multimodal agent, a good metric cannot just look at the final text response. It has to reflect whether the agent took the right actions, used the right tools, and held together across a multi-turn workflow.
At a high level, we think about performance at two levels: how well the agent does on a specific scenario, and how well it does across the full benchmark.
For a single scenario, the metric is the probability that the agent successfully completes that task. We break that into two parts. First, did the agent choose a valid plan for the turn? Second, conditional on choosing a valid plan, how accurately did it execute the necessary tool calls and parameters? The scenario score is then the product of those per-turn probabilities across the full conversation.

Here, \(T\) is the number of turns in the scenario and \(M\) is the number of repeated runs used to estimate the probability. Intuitively, the metric rewards the agent for both choosing the right overall path and executing that path correctly. If the plan is wrong, the tool-call score for that branch does not carry much meaning, which is why planning is treated as the first gate.
Across the full benchmark, we compute an overall success probability by taking a weighted average of the scenario-level probabilities. We weight by the number of turns in each scenario, since longer scenarios are generally harder and we do not want the benchmark to underrepresent them.

This gives us a top-line number that is easy to track over time, while still respecting the fact that not all scenarios have the same difficulty. The uncertainty is accumulated in quadrature, since each scenario is treated as an independent measurement.
The overall score is only part of the story. Once we have that top-line metric, we can also drill into more specific questions: which tools the agent overuses, which tools it struggles with, which parameters it gets wrong most often, and whether the final response itself has formatting or reference errors. Those lower-level diagnostics are often what actually help us improve the system.
Here is one example of how we use the benchmark in practice: comparing Gemini 3.1 Flash Lite against Gemini 3 Flash with both high- and low-thinking settings.
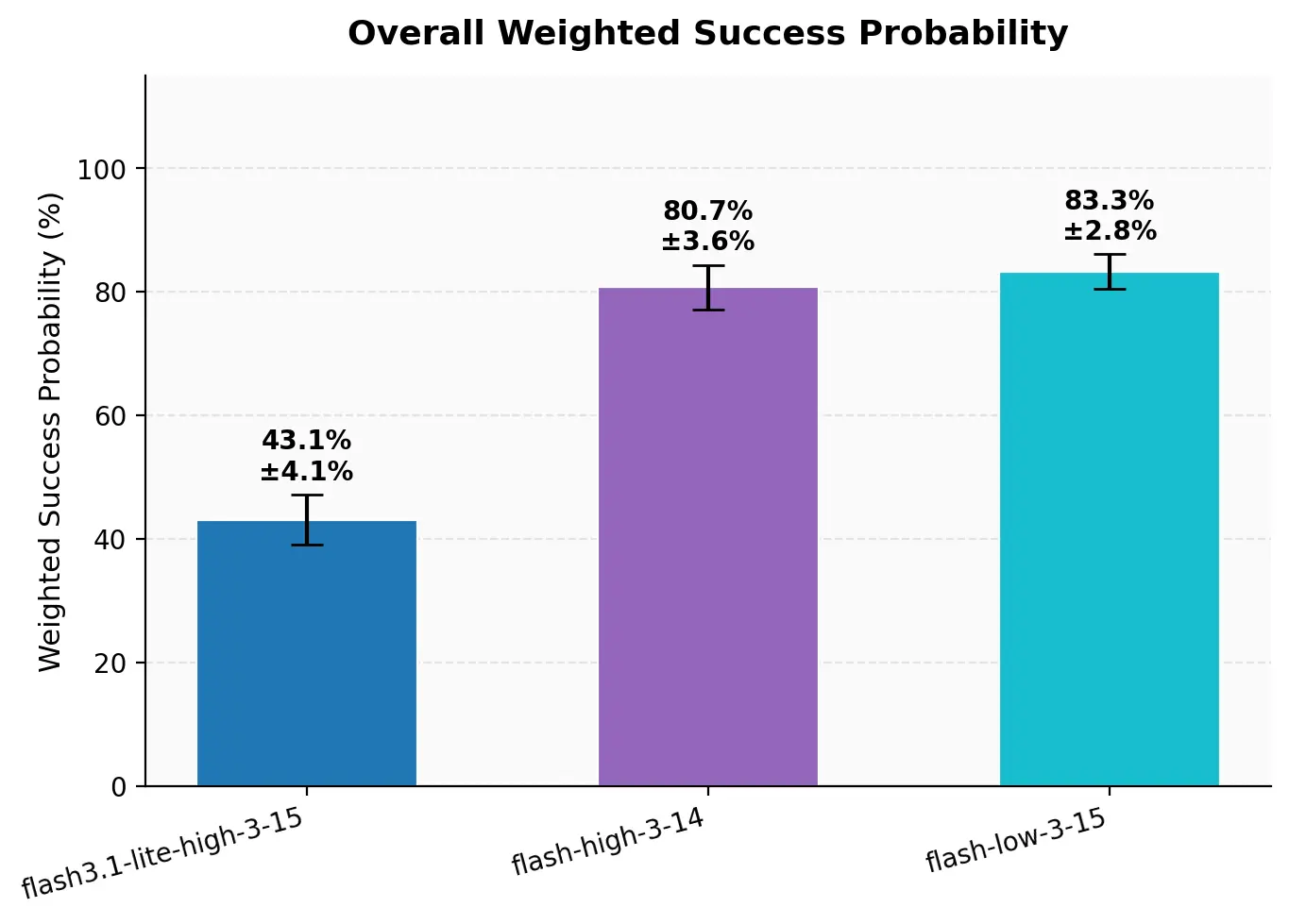
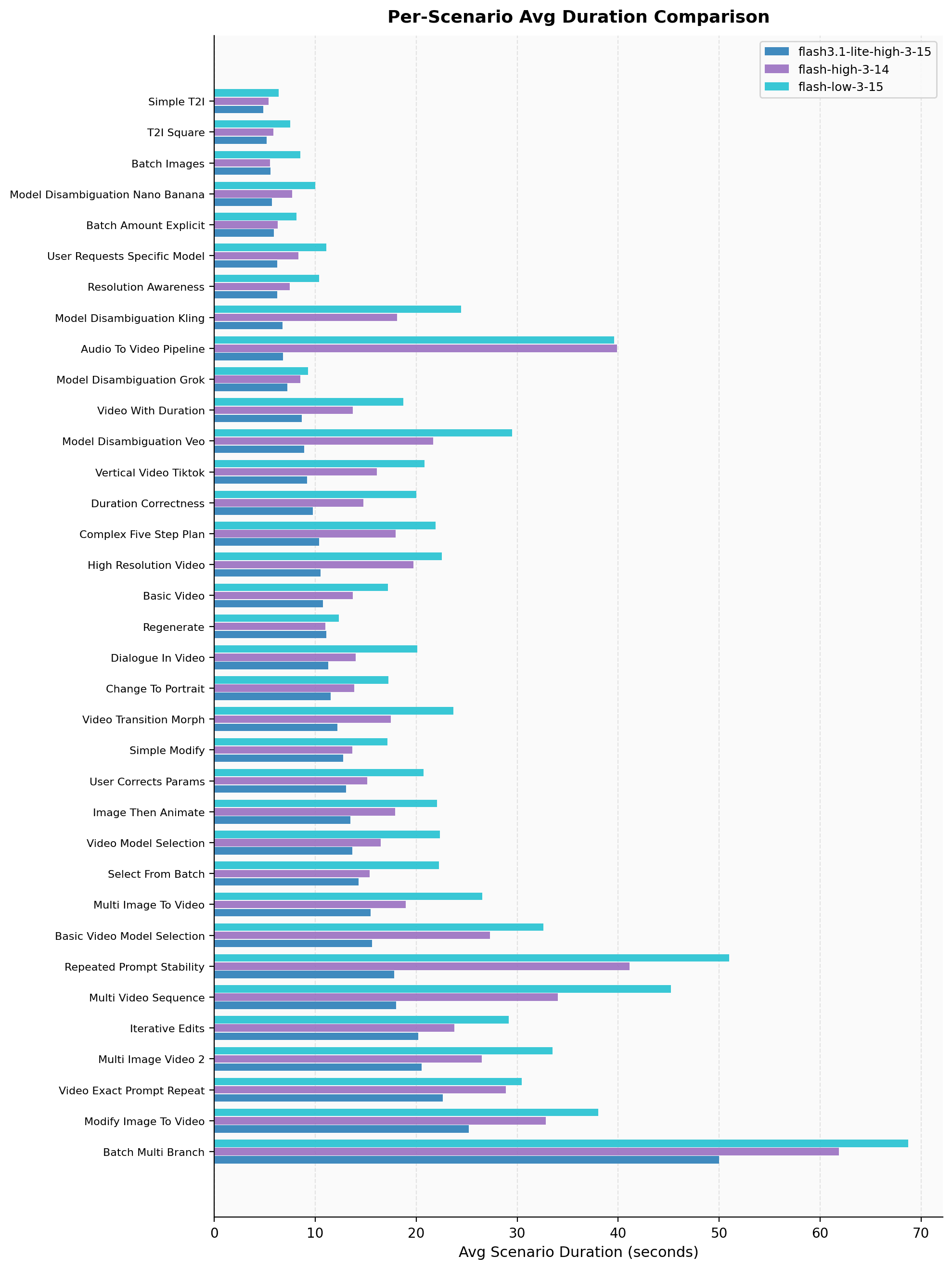
The results are a useful reminder that speed alone is not the whole story. Gemini 3.1 Flash Lite is much faster, but its performance is meaningfully worse. More surprisingly, Gemini 3 Flash Low performs about as well as High while actually taking longer. For our use cases, High thinking appears better at reaching the right conclusion and stopping earlier. From there, we can drill down into scenario-level detail to understand where those differences come from.
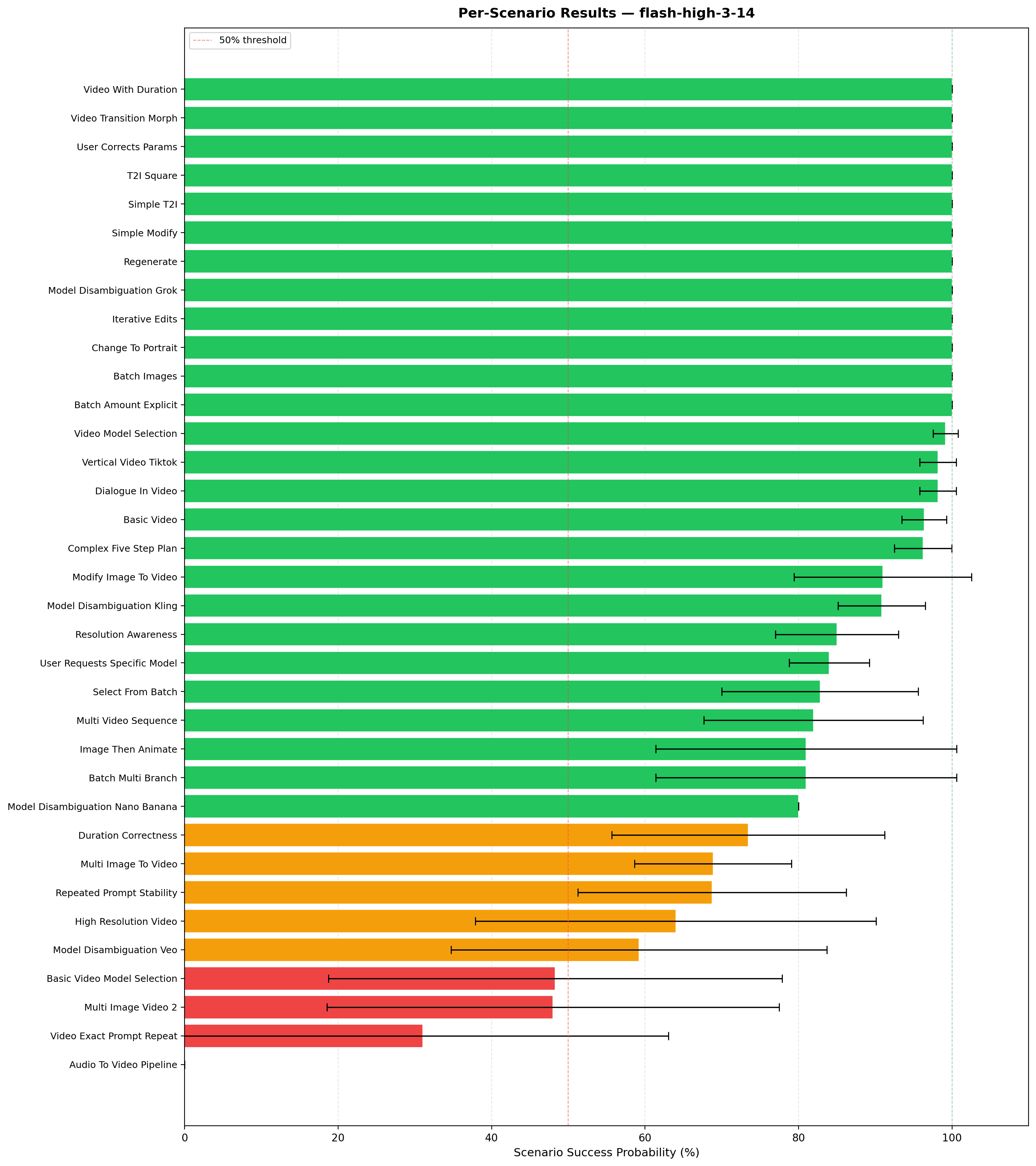
Wider error bars indicate higher variance in the results, which often suggests the agent is confused rather than consistently wrong. By contrast, consistently poor performance with small error bars points to a more systematic issue. Signals like this help our team decide where the biggest improvements are likely to come from.
Real world outcomes
One of the clearest benefits of having this eval framework is that it helps us make decisions faster.
In one case, we noticed the agent was effectively thinking itself into a loop. Earlier versions of the system included a primitive planning mode along with a series of injected reminders meant to guide the agent through difficult tasks. On paper, that extra structure seemed helpful. In practice, we started to suspect that our attempts to help were actually making the behavior worse by adding confusion and unnecessary overhead.
Because we had a benchmark in place, we did not have to rely on intuition alone. We ran the full evaluation suite with the planner and reminders enabled, and then again with them removed. The probability of success increased from roughly 40% to 60%.
That result made the decision clear. We removed the extra scaffolding and let the agent operate more directly. Without a benchmark, that kind of change would have been much harder to justify with confidence.
Conclusion
Building a multimodal agent is not just about making great demos. It also means building the systems that let you understand, measure, and improve behavior over time.
For us, that meant creating an eval framework that is realistic enough to capture real conversational workflows, cheap enough to run regularly, and structured enough to surface actionable insights. It helps us measure progress at the top level, diagnose failures at a more granular level, and make product decisions with more confidence.
That is the real value of this work. As agents become a more central part of creative software, strong evals are what turn a powerful but unpredictable system into something you can reliably improve.
Contributors:
Hedra Research Team
